一、内存管理机制介绍
在C/C++语言中,对内存的操作需要程序自行管理。不同于C/C++,Python提供了一系列机制来保障内存使用的高效与安全。避免了程序自行管理内存,使Python开发变得更加简单。Python的内存管理机制包含以下几方面:
- 对象池:Python 使用对象池来管理小整数和常用的字符串,以减少内存分配和释放的开销 (即我们前边文章提到的小整数池)
- 内存分配器:Python 使用自己的内存分配器(如 PyMalloc)来管理内存,这个分配器对小对象进行了优化
- 引用计数:每个对象都有一个引用计数,记录有多少个引用指向这个对象。当引用计数为零时,对象会被立即销毁
- 循环引用:引用计数无法处理循环引用(即两个对象相互引用),因此 Python 使用垃圾回收器来检测和清除循环引用
- 垃圾回收器:Python 的垃圾回收器基于分代回收机制,将对象分为不同的“代”,并根据对象的生命周期进行回收
- 内存池:通过内存池机制,Python 可以有效地管理小对象的内存分配,减少碎片化
- 标记清除:针对循环引用造成的内存泄漏,Python通过标记清除机制回收垃圾
- GIL:Python 的多线程受限于全局解释器锁(GIL),这意味着同一时刻只有一个线程可以执行 Python 字节码。这是为了保护内存管理的线程安全
二、直接引用和间接引用
在定义变量时,是在内存申请一块空间存储变量值,让后将变量值绑定给变量名。定义变量时为了使用,变量的引用方式就分为两种,直接引用和间接引用。如:
myname = 'wfj'
使用 myname 获取变量名就是直接引用。间接引用主要针对的是容器类型,如列表:
l = ['a', 'b', myname]
>>> print(id(myname), id(l[2]))
140086497139600 140086497139600
l[2] 这个元素就是间接引用。
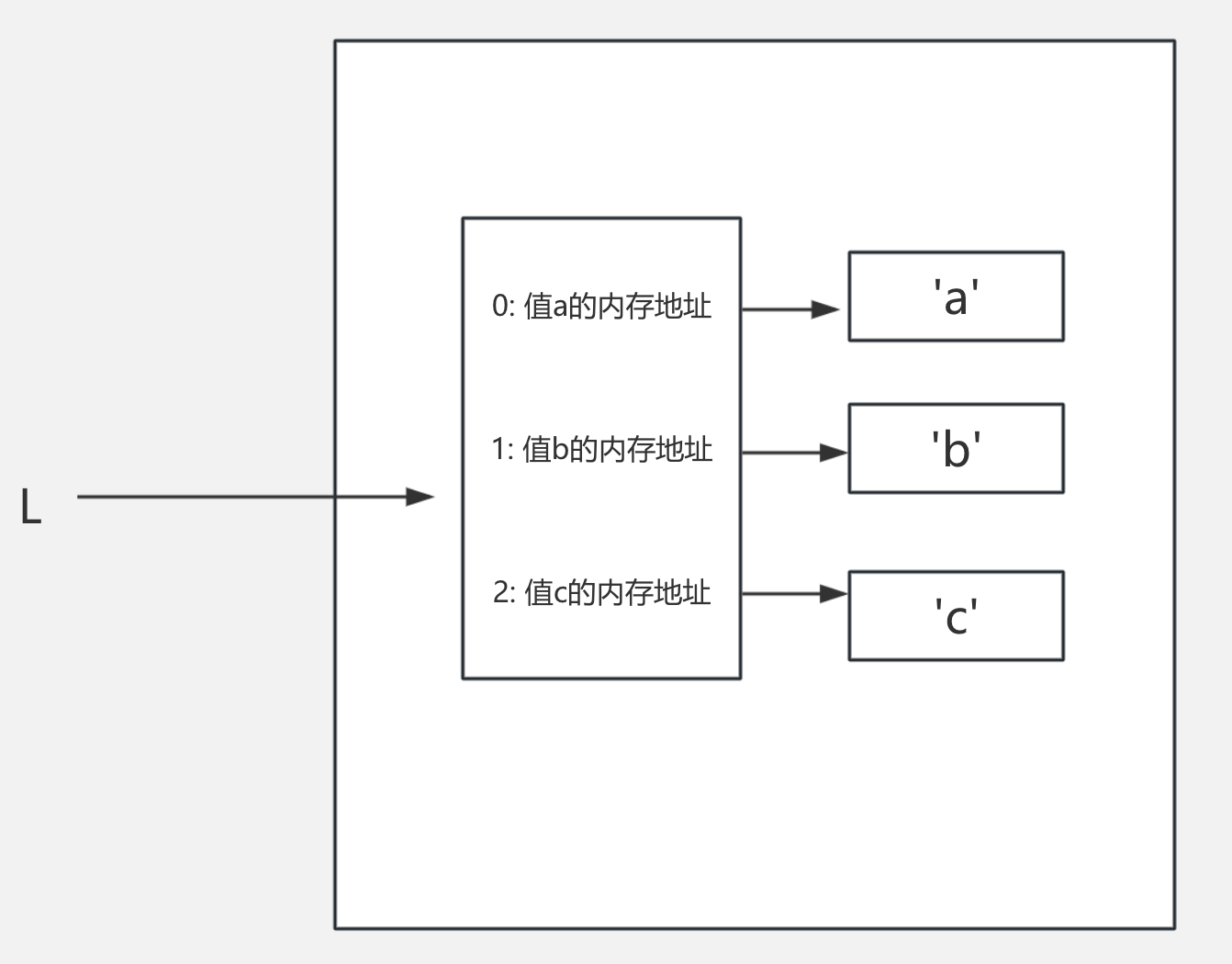
2.1、列表在内存中的存储方式
我们先看一个直接引用在内存中的存储方式:
a = 'wfj'
b = a
c = a
这种引用方式为直接引用。它会在在内存中开启一个空间存储值 ‘wfj’。然后定义三个变量 a, b, b 都绑定到这块内存空间。这时候引用计数就是3。我们再来看下列表,如:
l = ['a', 'b', 'c']
列表l在内存中是怎么存储的呢。首先先申请三块内存空间分别存储值’a’, ‘b’, ‘c’。然后再申请一块内存空间存储值’a’, ‘b’, ‘c’的内存地址,分别对应0,1,2三号索引地址。最后将这块内存空间绑定到变量l。这就是间接引用。同样字典类型存的是key的内存地址。
三、垃圾清除
3.1、循环引用
循环引用顾名思义就是,变量a引用了变量b,变量b引用了变量a。我们通过一个示例来看下:
>>> l1 = ['a', 'b']
>>> l2 = ['x', 'y']
>>> l1.append(l2)
>>> print(l1, id(l1[2]), id(l2))
['a', 'b', ['x', 'y']] 140086497166152 140086497166152
>>> l2.append(l1)
>>> print(l2, id(l2[2]), id(l1))
['x', 'y', ['a', 'b', [...]]] 140086497166088 140086497166088
>>> print(l1)
['a', 'b', ['x', 'y', [...]]]
这个示例中,我们先把l2添加到了l1里面,又把l1添加到l2里面。相当于l1里面引用了l2的内存地址,l2又引用了l1的内存地址。这时如果执行了 del l1, del l2。两个列表都无法访问了,但是相互之间存在间接引用,引用计数不为0,又无法被垃圾回收,就造成了内存泄漏。这时候Python就提供了标记清除机制来回收这部分内存。
3.2、标记清除机制
在我们定义变量时,需要开辟一块内存来存储变量值,通用变量名也需要存在内存中。变量名存储在栈区,变量值存储在堆区。当堆区的内存地址引用计数被标记为0被清除时,对应的栈区的变量也会被清除。接下来我们来看一下循环引用的图示:
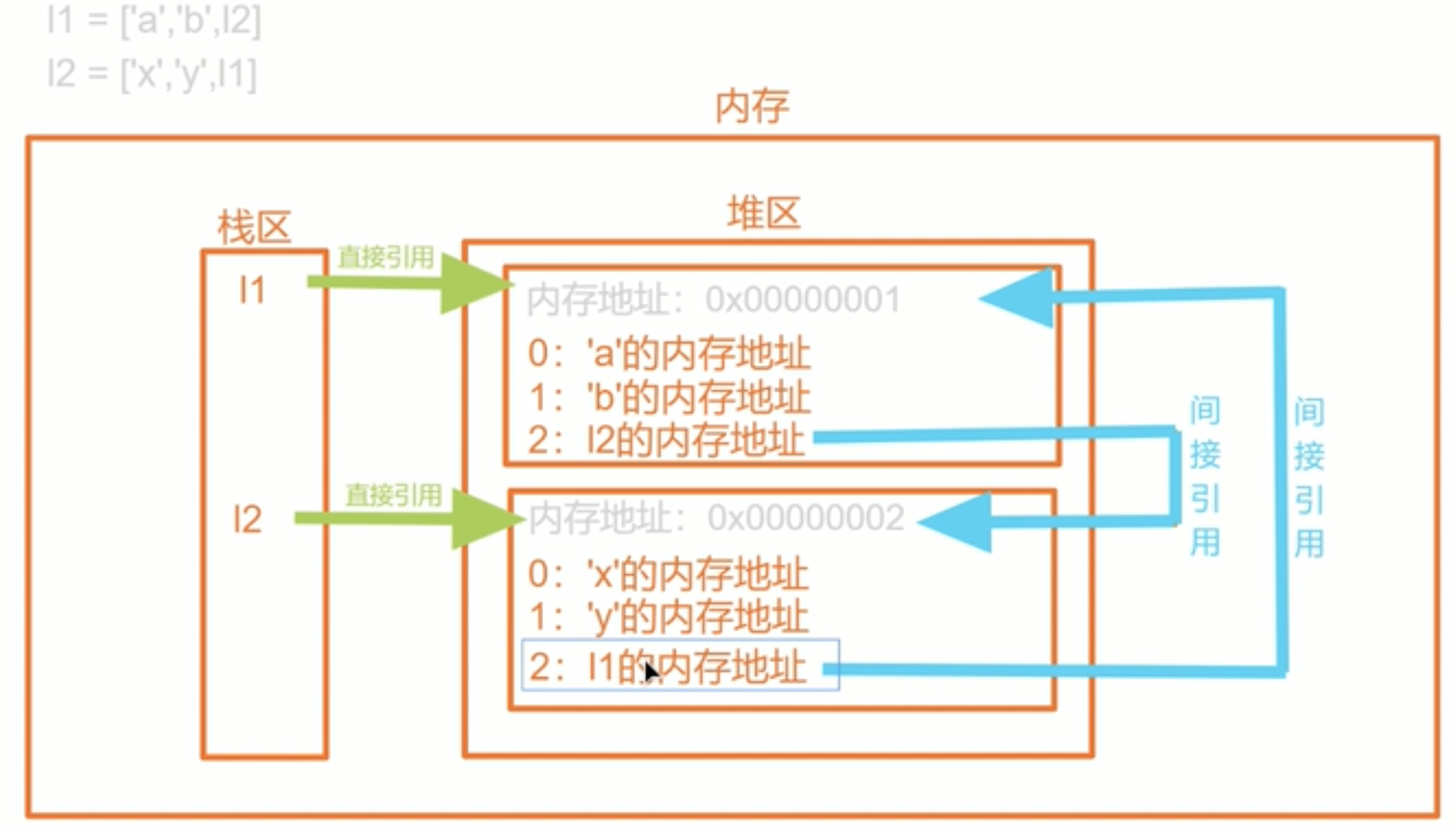 当直接引用被解除后。这两个列表还存在间接引用。这时候Python提供了一种标记清除的解决方案,标记清除会在Python程序内存空间不够用的时候,将程序暂停下来扫描战区。将栈区所有能引用到的值标记为存活状态,栈区引用不到的值标记为死亡状态,死亡状态的值就会被清理掉。
当直接引用被解除后。这两个列表还存在间接引用。这时候Python提供了一种标记清除的解决方案,标记清除会在Python程序内存空间不够用的时候,将程序暂停下来扫描战区。将栈区所有能引用到的值标记为存活状态,栈区引用不到的值标记为死亡状态,死亡状态的值就会被清理掉。
3.3、分代回收机制
目前垃圾回收机制已经具备回收所有垃圾的能力了,但是仍然存在弊端。当我们的变量很多时,垃圾回收需要遍历一次全部变量才能回收所有垃圾,这样效率会很低。于是Python提供了分代回收机制,一共分为三个代,新生成的对象加入第0代,每次都进行全量扫描。存在变量每次扫描都是存活,达到Python的设定的阈值时,就会把该变量加入到第1代,这时就会降低第1代的扫描频率,当第1代中的变量扫描存在变量每次都存活且达到Python的阈值时,就把该变量加入到第2代,进一步降低第2代的扫描频率。这样就不会每次都遍历所有变量了。
关于Python的垃圾回收机制,我们就了解这么多就可以了。不必去深究具体的阈值和实现机制。想跟深入的了解,可以查看其他资料文章,参考: Python垃圾回收机制
「真诚赞赏,手留余香」
 WangFuJie Blog
WangFuJie Blog
真诚赞赏,手留余香
使用微信扫描二维码完成支付
